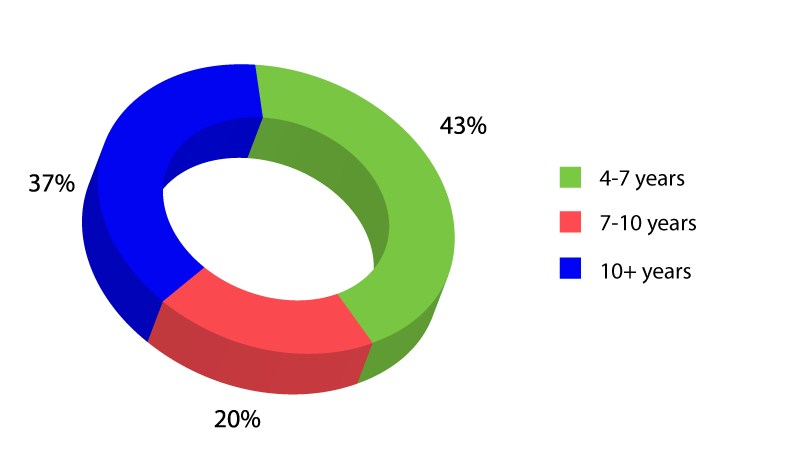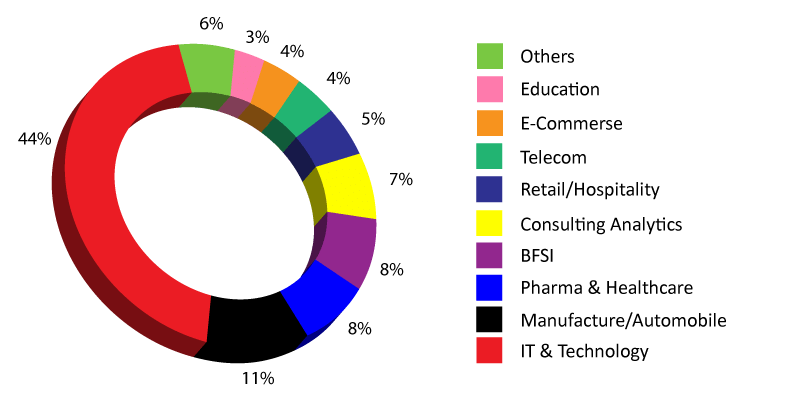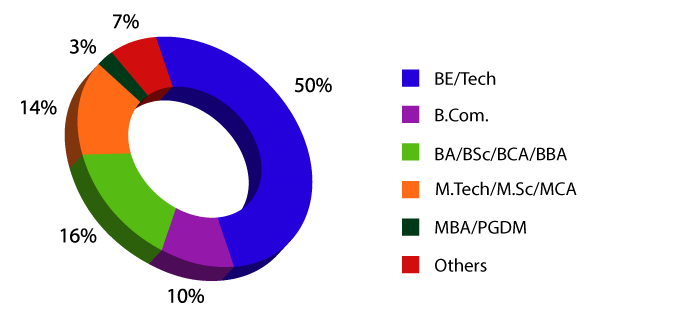PG in Data Science
PG Program in Data Science and Engineering
- Data Science Course with Placement Assistance
Enquire 080-4718-9253

Data Science Bootcamp designed to deliver career outcome
Great Learning & Great Lakes’ PGP-DSE is a classroom program designed for fresh graduates and early career professionals. With the large number of job openings in analytics and data science, PGP-DSE equips you with the right skills and knowledge needed to break into these roles.

 Watch Video
Watch Video
After the completion
of the program

85%
Avg Salary Hike*

43 LPA
Highest CTC

3300+
Hiring Companies

3000+
Students Placed
*The statistics mentioned above pertain specifically to this program and are contingent upon the job market condition at that time.
After 3-4 years
of program completion
17.45 LPA
Average CTC of program learners
550% Hike
for experienced professional
320% Hike
for freshers & young professionals
Get Industry ready with Dedicated Career Support

Dedicated Placement drives for our learners

1:1 live career mentorship with industry experts

Personalised Resume & Linkedin Review

1:1 mock interviews with industry experts

Access to exclusive job postings from Great Learning job portal
Designed for early-career professionals like you
Immersive Classroom
Learning Format
In-class lab sessions Monday to Thursday in 5 cities Bangalore, Chennai, Gurgaon, Pune, Hyderabad

Weekly mentorship
by experts
Get assistance on projects and reinforce concepts through weekly sessions

Network with people of
similar interests
Interact with peers to grow your professional network

Dedicated
Program Support
Dedicated Program Manager to solve your queries

Certificate from Great Lakes Executive Learning

PGP - Data Science & Engineering from Great Lakes
Data Science Bootcamp designed by India’s best Faculty to deliver career outcome

Great Lakes Executive Learning
View Sample Certificate
Top Standalone Institution
*Outlook India
Private B-Schools
*Careers360
Non-IIM/IIT Institute
*NIRF
Ace Power BI Certification with an Add-on Course


PGP in Data Science and Engineering + Power BI Data Analyst Training Program
All the features of PG Program +
-

Live Virtual Classes with Microsoft Certified Instructors
-
Hands-on Learning and Academic Support
-
Exam Preparation Guide
-
Mock Exams

Comprehensive Curriculum
The curriculum has been designed by faculty from Great Lakes and highly skilled and deeply knowledgeable. experts of data science.

225+ hrs
Learning content
5+
Languages & Tools
Foundations
The Foundations block comprises four courses where we get our hands dirty with the introduction to Python, Exploratory Data Analysis, Statistics, SQL Programming, and some domain-specific knowledge head-on. These courses set our foundations so that we sail through the rest of the journey with minimal hindrance.
- Syntax and Semantics of Python programming
- Conditional statements
- Loops
- Iterators
- User-defined functions
- NumPy
- Pandas
This module will let us get comfortable with the Python programming language used for Data Science. We start with a high-level idea of Object-Oriented Programming and later learn the essential vocabulary(/keywords), grammar(/syntax) and sentence formation(/usable code) of this language.
Python is a widely used high-level programming language and has a simple, easy-to-learn syntax that highlights readability. This module will help you drive through all the fundamentals of programming in Python, such as syntax and semantics, and at the end, you will execute your first Python program.
Conditional Statements perform various operations based on a boolean condition that evaluates to true or false. In this module, you will learn to implement if-else statements in Python.
A loop is used for executing one or more statements several times mentioned. It will repeat the sequence of information until it meets a specified condition. This module will teach you how to implement for and while loops.
Iterators are objects containing values, where you can traverse through them. This module will teach you how to implement Iterator methods like __iter__() and __next__().
User-defined functions are functions created by the programmer to perform any application-specific operations. In this module, you will implement user-defined functions in Python using the def keyword.
This module will give you a deep understanding of exploring data sets using NumPy. NumPy is one of the most widely used Python libraries. NumPy is a package for scientific computing like working with arrays.
Pandas is also one of the most widely used Python libraries. Pandas is used to analyse and manipulate data. This module will give you a deep understanding of exploring data sets using Pandas.
- Pandas
- Summary statistics (mean, median, mode, variance, standard deviation)
- Seaborn
- matplotlib
This module of PG in Data Science courses will teach you all about Exploratory Data Analysis like Pandas, Seaborn, Matplotlib, and Summary Statistics.
Pandas is one of the most widely used Python libraries. Pandas is used to analyse and manipulate data. This module will give you a deep understanding of exploring data sets using Pandas.
In this module, you will learn about various statistical formulas and implement them using Python.
Seaborn is also one of the most widely used Python libraries. Seaborn is a Matplotlib based data visualisation library in Python. This module will give you a deep understanding of exploring data sets using Seaborn.
Matplotlib is another widely used Python libraries. Matplotlib is a library to create statically animated, interactive visualisations. This module will give you a deep understanding of exploring data sets using Matplotlib.
- Probability distribution
- Normal distribution
- Poisson's distribution
- Bayes’ theorem
- Central limit theorem
- Hypothesis testing
- One Sample T-Test
- Anova and Chi-Square
In the next module, you will learn everything you need to know about all the statistical methods used for decision making in this Data Science PG course.
A statistical function reporting all the probable values that a random variable takes within a specific range is known as a Probability Distribution. This module will teach you about Probability Distributions and various types like Binomial, Poisson, and Normal Distribution in Python.
Normal Distribution is the most critical Probability Distribution in Statistics, which describes the distribution of values of a variable.
Poisson's Distribution is a Probability Distribution in Statistics, which determines an event’s occurrence within a specified time interval.
Baye’s Theorem is a mathematical formula named after Thomas Bayes, which determines conditional probability. Conditional Probability is the probability of an outcome occurring predicated on the previously occurred outcome.
This module will teach you how to estimate a normal distribution using the Central Limit Theorem (CLT).
This module will teach you about Hypothesis Testing in Statistics. Hypothesis Testing is a necessary procedure in Applied Statistics for doing experiments based on the observed/surveyed data.
One-Sample T-Test is a Hypothesis testing method used in Statistics. In this module, you will learn to check whether an unknown population mean is different from a specific value using the One-Sample T-Test procedure.
Analysis of Variance, also known as ANOVA, is a statistical technique used in Data Science,
which is used to split observed variance data into various components for additional
analysis and tests.
Chi-Square is a Hypothesis testing method used in Statistics, which is used to measure how a
model compares to actual observed data.
This module will teach you how to identify the significant differences between the means of
two or more groups.
- Introduction to DBMS
- ER diagram
- Schema design
- Key constraints and basics of normalization
- Joins
- Subqueries involving joins and aggregations
- Sorting
- Independent subqueries
- Correlated subqueries
- Analytic functions
- Set operations
- Grouping and filtering
Here, we will cover everything you need to know about SQL programming, such as DBMS, Normalization, Joins, etc.
Database Management Systems (DBMS) is a software tool where you can store, edit, and
organise data in your database.
This module will teach you everything you need to know about DBMS.
An Entity-Relationship (ER) diagram is a blueprint that portrays the relationship among
entities and their attributes.
This module will teach you how to make an ER diagram using several entities and their
attributes.
Schema design is a schema diagram that specifies the name of record type, data type, and other constraints like primary key, foreign key, etc. It is a logical view of the entire database.
Key Constraints are used for uniquely identifying an entity within its entity set, in which
you have a primary key, foreign key, etc. Normalization is one of the essential concepts in
DBMS, which is used for organising data to avoid data redundancy.
In this module, you will learn how and where to use all key constraints and normalization
basics.
As the name implies, a join is an operation that combines or joins data or rows from other
tables based on the common fields amongst them.
In this module, you will go through the types of joins and learn how to combine data.
This module will teach you how to work with subqueries/commands that involve joins and aggregations.
As the name suggests, Sorting is a technique to arrange the records in a specific order for a clear understanding of reported data. This module will teach you how to sort data in any hierarchy like ascending or descending, etc.
The inner query that is independent of the outer query is known as an independent subquery. This module will teach you how to work with independent subqueries.
The inner query that is dependent on the outer query is known as a correlated subquery. This module will teach you how to work with correlated subqueries.
A function that determines values in a group of rows and generates a single result for every row is known as an Analytic Function.
The operation that combines two or more queries into a single result is called a Set Operation. In this module, you will implement various set operators like UNION, INTERSECT, etc.
Grouping is a feature in SQL that arranges the same values into groups using some functions
like SUM, AVG, etc.
Filtering is a powerful SQL technique, which is used for filtering or specifying a subset of
data that matches specific criteria.
Machine Learning Techniques
The next module is Machine Learning that will teach us all the Machine Learning techniques from scratch, and the popularly used Classical ML algorithms that fall in each of the categories.
- Multiple linear regression
- Fitted regression lines
- AIC, BIC, Model Fitting, Training and Test Data
- Introduction to Logistic regression, interpretation, odds ratio
- Misclassification, Probability, AUC, R-Square
This module will get us comfortable with all the techniques used in Linear and Logistic Regression.
Multiple Linear Regression is a supervised machine learning algorithm involving multiple
data variables for analysis. It is used for predicting one dependent variable using various
independent variables.
This module will drive you through all the concepts of Multiple Linear Regression used in
Machine Learning.
A fitted regression line is a mathematical regression equation on a graph for your data. This model can be used to identify the relationship between a predictor variable (x-scale) and a response variable (y-scale) so that it can assess whether the model fits your data.
In this module, you will go through everything you need to know about several models such as AIC, BIC, Model Fitting, Training, and Test Data.
Logistic Regression is one of the most popular ML algorithms, like Linear Regression. It is
a simple classification algorithm to predict the categorical dependent variables with the
assistance of independent variables.
This module will drive you through all the Logistic Regression concepts used in Machine
Learning, interpret Machine Learning models, and find the odds ratio relationship.
This module will teach everyone how to work with Misclassification, Probability, AUC, and R-Square.
- CART
- KNN (classifier, distance metrics, KNN regression)
- Decision Trees (hyper parameter, depth, number of leaves)
- Naive Bayes
In the next module, you will learn all the Supervised Learning techniques used in Machine Learning.
CART, also known as Classification And Regression Tree, is a predictive machine learning
model that describes the prediction of outcome variable's values predicated on other values.
You will learn about the usage of this predictive model in this module.
KNN or k-Nearest Neighbours algorithm is one of the most straightforward machine learning
algorithms for solving regression and classification problems.
You will learn about using this algorithm like classification, distance metrics, and KNN
regression through this module.
Decision Tree is a Supervised Machine Learning algorithm used for both classification and
regression problems. It is a hierarchical structure where internal nodes indicate the
dataset features, branches represent the decision rules, and each leaf node indicates the
result.
You will learn about hyperparameter, depth, and the number of leaves in this module.
Naive Bayes Algorithm is used to solve classification problems using Baye’s Theorem. This module will teach you about the theorem and solving the problems using it.
- Clustering - K-Means & Hierarchical
- Distance methods - Euclidean, Manhattan, Cosine, Mahalanobis
- Features of a Cluster - Labels, Centroids, Inertia
- Eigen vectors and Eigen values
- Principal component analysis
In the next module, you will learn all the Unsupervised Learning techniques used in Machine Learning.
Clustering is an unsupervised learning technique involving the grouping of data. In this
module, you will learn everything you need to know about the method and its types, like
K-means clustering and hierarchical clustering.
K-means clustering is a popular unsupervised learning algorithm to resolve the clustering
problems in Machine Learning or Data Science.
Hierarchical Clustering is an ML technique or algorithm to build a hierarchy or tree-like
structure of clusters. For example, it is used to combine a list of unlabeled datasets into
a cluster in the hierarchical structure.
This module will teach you how to work with all the distance methods or measures such as Euclidean, Manhattan, Cosine, and Mahalanobis.
This module will drive you through all the features of a Cluster like Labels, Centroids, and Inertia.
In this module, you will learn how to implement Eigenvectors and Eigenvalues in a matrix.
Principal Component Analysis is a technique to reduce the complexity of a model, like eliminating the number of input variables for a predictive model to avoid overfitting.
- Bagging & Boosting
- Random Forest
- AdaBoost & Gradient boosting
- Hackathon
In this Machine Learning, we discuss supervised standalone models’ shortcomings and learn a few techniques, such as Ensemble techniques, to overcome these shortcomings.
Bagging, also known as Bootstrap Aggregation, is a meta-algorithm in machine learning used
for enhancing the stability and accuracy of machine learning algorithms, which are used in
statistical classification and regression.
As the name suggests, Boosting is a meta-algorithm in machine learning that converts robust
classifiers from several weak classifiers. Boosting can be further classified as Gradient
boosting and ADA boosting or Adaptive boosting.
Random Forest is a popular supervised learning algorithm in machine learning. As the name indicates, it comprises several decision trees on the provided dataset’s several subsets. Then, it calculates the average for enhancing the dataset’s predictive accuracy.
Boosting can be further classified as Gradient boosting and ADA boosting or Adaptive boosting. This module will teach you about Gradient boosting and ADA boosting.
Hackathon is an event usually hosted by a tech organisation, where computer programmers gather for a short period to collaborate on a software project.
Applications*
The last topic in this Data Science and Engineering course covers applications like Time Series, Text Mining, and Data Visualization.
- Trend and seasonality
- Decomposition
- Smoothing (moving average)
- SES, Holt & Holt-Winter Model
- AR, Lag Series, ACF, PACF
- ADF, Random walk and Auto Arima
This block will teach you all the techniques involved in Time Series.
Trend is a systematic linear or non-linear component in Time Series metrics, which changes
over a while and does not repeat.
Seasonality is a systematic linear or non-linear component in Time Series metrics, which
changes over a while and repeats.
This module will teach you how to decompose the time series data into Trend and Seasonality.
This module will teach you how to use this method for univariate data.
SES, Holt, and Holt-Winter Models are various Smoothing models, and you will learn everything you need to know about these models in this module.
In this module, you will learn about AR, Lag Series, ACF, and PACF models used in Time Series.
In this module, you will learn about ADF, Random walk, and Auto Arima techniques used in Time Series.
- Text cleaning, regular expressions, Stemming, Lemmatization
- Word cloud, Principal Component Analysis, Bigrams & Trigrams
- Web scrapping, Text summarization, Lex Rank algorithm
- Latent Dirichlet Allocation (LDA) Technique
- Word2vec Architecture (Skip Grams vs CBOW)
- Text classification, Document vectors, Text classification using Doc2vec
In this module, you will learn how to convert unstructured text into a structured text to discover relevant insights. This method is known as Text Data Mining.
Text Cleaning is a necessary procedure to emphasize the attributes for your machine learning model to choose. Regular Expression is a language that states text search strings. Stemming is a technique used in Natural Language Processing (NLP), which plucks out the base form of words by the removal of affixes from the words. Lemmatization is another commonly used NLP technique, which combines the different inflected word forms to be analysed as a single item.
A word cloud is a data visualization technique, which is used to represent text data. This module will make you learn everything about Word cloud, Principal Component Analysis, Bigrams, and Trigrams used in Data Visualization.
Web Scraping is the process of extracting data from the web. This module will teach you how to collect and parse data using Web Scraping and learn how to implement Text Summarization and Lex Rank algorithm.
The word ‘Latent’ indicates that the model discovers the ‘yet-to-be-found’ or hidden topics from the documents. ‘Dirichlet’ indicates LDA’s assumption that the distribution of topics in a document and the distribution of words in topics are both Dirichlet distributions. ‘Allocation’ indicates the distribution of topics in the document.
Word2vec is a method to create word embeddings by using a two-layer neural network
efficiently. It was developed by Tomas Mikolov et al. at Google in 2013 to make the
neural-network-based training of the embedding more efficient and since then has become the
de facto standard for developing pre-trained word embedding.
In this module, you will learn about the differences between Skip Grams and CBOW (Continuous
Bag of Words).
In this module, you will learn even more about Text Classification and Document Vectors using Doc2vec.
- Building interactive dashboards using Tableau
- Data Visualization using Tableau
The last topic in this PG in Data Science program is Data Visualization. The process of the graphical representation of data and information is known as Data Visualization. This module will teach you how to use data visualization tools for providing data trends and patterns.
In this module, you will learn how to create an interactive Tableau dashboard and charts to organise data.
Tableau is the most widely used data visualization tool to solve problems. This module will teach you everything you need to know about Data Visualization using Tableau.
*Online Instruction
Capstone Project
You will get your hands dirty with real-time projects under industry experts’ guidance, from Data Science, using Python to Machine Learning, SQL and Tableau. Successful completion of the project will earn you a post-graduate in Data Science and Engineering course.
Career Preparation: Aptitude Skill Training and Development, Resume Review Workshops, Interview Preparation
This post-graduate program in Data Science and Engineering will guide you through your career path with Aptitude Skill Training and Development. The program will also guide you in building your professional resume, attending mock interviews to boost your confidence and nurture you to nail your professional interviews.
PG Certificate from Great Lakes Executive Learning
Earn a Postgraduate Certificate in the top-rated Data Science and Engineering course from Great
Lakes Executive Learning.
Its exhaustive Curriculum will foster you into a highly-skilled professional and help you land a job
at the world’s leading corporations.
Exclusive Campus Hiring Drives
If you are looking for a Data Science course with placement opportunities, this is the right Data Science and Engineering course to excel in your career. This course offers you exclusive campus hiring opportunities with three months of placement assistance after the program completion.
Languages and Tools covered





Hands-on Projects
Data sets from the industry

1000+
Projects completed
15+
Domains





Learner Testimonials
"Thanks to the DSE program at Great Lakes, I got 2 job offers, one from DXC Technology and another from Razorthink. This program is an ideal mix of both theory and hands-on practice. Taking this course to upskill myself was one of the best decisions I’ve made.
Suraj Suresh
Data Scientist

"Capstone projects gave a lot of insights about the real life industry problems and issues. Career counselling sessions helped me ace multiple interview rounds. The program is ideal for any Fresher who wants to learn data science and make a rewarding career out of it.
Isha Nair
Data Analyst
"2-Year career gap didn’t stop me from bagging a position as a consultant at Fractal Analytics. Thank you Great Learning.
Mahendra Shaji
Analytics Consultant
"The program is very well structured and an ideal combination of theory and hands-on practice. I got 2 job offers even before completing the course.
Naga Pavan
Consultant Analyst

"The mentorship sessions with industry experts helped me become industry ready. I am now working on libraries I never knew of earlier. The journey from an economics background to being a data analyst has been really amazing.
Nayantara
Data Analyst
"The thing I liked most about the program was the quality of education. The faculty have lots of experience in their fields and they cleared all our doubts. I got opportunities in 2 companies, one in HSBC and the other in Genpact.
Utkarsh Sharma
Risk Analyst
"At Great Learning, we are the proudest when our learners achieve the outcomes they’ve been aspiring for. Here is what some of our candidates have to share about their Great Lakes DSE program experience.
C Jagadeesh
Data Scientist
"The DSE Program has been designed to help candidates jumpstart their careers in the field of Data Science. Hear from our candidates as they share their program experience and transition stories.
Ankita Shinde
Data Analyst
Program Fees
Starting at ₹ 8824/month*
Program Fee: ₹ 3,50,000 + GST

Learn Now, Pay Later
Pursue the course that lasts for 5 months and start paying the fees from the 6th month with flexible fee payment plans to help you kickstart your learning journey in two simple steps:
STEP 1
Pay the admission fee to confirm enrollment and start learning.
STEP 2
Process the remaining program fee via simple loan installment options.
Payment Partners

*Subject to approval by payment partners
Benefits of learning from us
- 5-Month Program
- Immersive Classroom Learning Format
- Designed for freshers and early career professionals
- Comprehensive curriculum and hands-on learning
- World class faculty
- Industry oriented Capstone Project
- PG Certificate from Great Lakes
- Aptitude skill training and development
- Resume building and mock interview sessions
- Placement drives with India’s leading companies
“In just 2 years of course completion, I was able to get an exponential salary hike of around 500%.”

Shawrya Sharma
Advanced Insight Analyst
Expedia Group
Take Your Data Science Skills to the Next Level with Add-On Courses
PGP in Data Science and Engineering + Power BI Data Analyst Training Program
All the features of PG Program +
-
Live Virtual Classes with Microsoft Certified Instructors
-
Hands-on Learning and Academic Support
-
Exam Preparation Guide
-
Mock Exams
Inclusive of the total program fee + Microsoft Power BI fee
Application Process
Fill the application form
Apply by filling a simple online application form.
Admissions Test & Interview
Go through an admission test and a screening call with the Admission Director’s office..
Join program
An offer letter will be rolled out to the select few candidates. Secure your seat by paying the admission fee.
Upcoming Application Deadline
Our admissions close once the requisite number of participants enroll for the upcoming batch. Apply early to secure your seats.
Deadline: 15th May 2024
Apply NowBatch Start Date
Frequently Asked Questions
PGP-DSE is a 5-months classroom program. Also, get assistance on projects and reinforce concepts through weekly mentorship sessions by experts with a dedicated program manager to solve your queries
Great Lakes Executive Learning and Microsoft awards PG Data Science and PowerBI Data Analytics certification upon completing the Data Science Engineering and PowerBI Data Analyst training program. This Microsoft Power-BI Data Analytics certification serves as an official recognition of the graduate's accomplishment in meeting the comprehensive course requirements and demonstrates their proficiency in the Data Science and Power BI Data Analysis domains.
In the PG Data Science certificate course, evaluation is conducted through a structured and continuous assessment framework. This rigorous and comprehensive program employs case studies, quizzes, assignments, and project reports to evaluate learners’ progress. These diverse assessment tools are designed to meticulously measure learners’ understanding and application of the course material, ensuring a thorough and well-rounded appraisal, offering Microsoft Data Analytics certification to demonstrate their proficiency in data science and data analytics.
The PG Data Science course is open for candidates in their final semester and recent graduates with 0-3 years of experience. Applicants should also have 60% or above in Xth, XIIth, and Bachelor's. Apply Now for Data Science Course Demo.
Related Programs for you
Still have queries? Contact Us
Please fill in the form and an expert from the admissions office will call you in the next 4 working hours. You can also reach out to us at dse@greatlearning.in or 080-4718-9253
Download Brochure
Check out the program and fee details in our brochure
Help us understand you better
What matters the most to you in a Data Science & Engineering course?
We are allocating a suitable domain expert to help you out with your queries. Expect to receive a call in the next 4 hours.